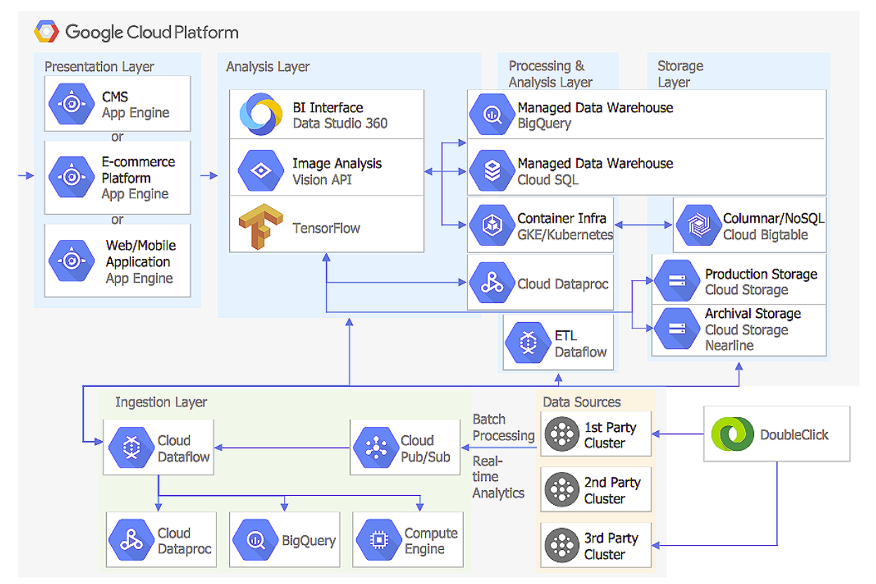
About Dataproc
Dataproc is a managed Spark and Hadoop service that lets you take advantage of open source data tools for batch processing, querying, streaming, and machine learning. Dataproc automation helps you create clusters quickly, manage them easily, and save money by turning clusters off when you don’t need them.Cloud Dataproc also Supports Hadoop,pig,Hive and Spark and has high level API’s for Job Submission.It also offers connectors to BIgquery,BigTable ,Cloud Storage and so on.
The below diagram shows the architecture of the dataproc and how the process takes place from end to end
Comparison of Dataproc Serverless and Dataproc Compute Engine
Dataproc serverless lets you run spark workloads without requiring you to provision and manage your own dataproc cluster.
Processing Frameworks :
Batch : Run time version 2.1 (spark 3.4, Java 17,scala 2.13) and earlier versions
Interactive : Pyspark kernals for spark 3.4 and earlier versions
Dataproc compute Engine is ideal if you want to provision and manage infrastructure, then execute workloads on spark and other open source processing frameworks.
Processing Frame works :
Spark 3.3 and other open source frameworks, such as Hive,Flink,Trino and kafka
The following table lists key differences between the Dataproc on Compute Engine and Dataproc Serverless for Spark.
| Capability | Dataproc Serverless for Spark | Dataproc on Compute Engine |
| Processing frameworks | Batch: Spark 3.4 and earlier versions Interactive: PySpark kernels for Spark 3.4 and earlier versions | Spark 3.3 and earlier versions. Other open source frameworks, such as Hive, Flink, Trino, and Kafka |
| Serverless | Yes | No |
| Startup time | 60s | 90s |
| Infrastructure control | No | Yes |
| Resource management | Spark based | YARN based |
| GPU support | Planned | Yes |
| Interactive sessions | Yes | No |
| Custom containers | Yes | No |
| VM access (for example, SSH) | No | Yes |
| Java versions | Java 17, 11 | Previous versions supported |
| OS Login support | No | Yes |
Advantages of Dataproc over on-prem
Low Cost :
Dataproc is priced at only 1 cent per virtual CPU in your cluster per hour, on top of the other Cloud Platform resources you use. Dataproc charges you only for what you really use with second-by-second billing and a low, one-minute-minimum billing period.
Super Fast:
Dataproc clusters are quick to start, scale, and shutdown, with each of these operations taking 90 seconds or less, on average. This means you can spend less time waiting for clusters and more hands-on time working with your data.
Integrated :
Dataproc has built-in integration with other Google Cloud Platform services, such as BigQuery, Cloud Storage, Cloud Bigtable, Cloud Logging, and Cloud Monitoring, so you have more than just a Spark or Hadoop cluster—you have a complete data platform.
Managed :
Use of spark and hadoop clusters without using the assistance of an administrator .Once your are done with the cluster, you can trun off the cluster so we can save the money.
There are Two type of scaling :
- Horizontal scaling :
- More Efficint for Single machines.
- Vertical scaling :
- More Machines running together.
Dataproc Components :
When you create a cluster, standard Apache Hadoop ecosystem components are automatically installed on the cluster
Below are the some of the components that are included
- Hive
- Anaconda
- Docker
- Flink
- Jupyter NoteBook
- Hbase
- Presto
- Zepplin Notebook
Below are the list of Compute Engine Machine Types:
- General Purpose :
Best price-performance ratio for a variety of workloads
- Storage Optimized :
Best for workloads that are low in core usage and high in Storage density
- Compute Optimized :
Highest performance per core on compute Engine and optimized for compute intensive workloads.
- Memory optimized :
Ideal for memory- intensive workloads, offering more memory power per core.
- Accelerator -optimized :
Ideal for massively parallelized Compute Unified Device Architecture (CUDA) compute workloads, such as machine learning (ML) and high performance computing (HPC).
Dataproc Serverless :
Dataproc Serverless lets you run spark workloads without requiring you to provision and manage your own dataproc cluster.
There are two ways to run the Dataproc Serverless workloads :
- Dataproc Serverless for Spark Batch :
Use the google cloud console, Google Cloud CLI or Dataproc API to submit a batch workload to the dataproc serverless service. The service will run the workload on a managed compute infrastructure, autoscaling resources as need .
- Dataproc serverless for spark Interactive :
Write and run code in Jupyter Notebooks. Use the Jupyter lab plugin to create multiple notebook sessions from templates that you create and manage.

Dataproc Serverless Pricing :
- Dataproc Serverless for Spark pricing is based on the number of Data Compute Units (DCUs), the number of accelerators used, and the amount of shuffle storage used. DCUs, accelerators, and shuffle storage are billed per second, with a 1-minute minimum charge for DCUs and shuffle storage, and a 5-minute minimum charge for accelerators.
- Memory used by Spark drivers and executors and system memory usage are counted towards DCU(Data Compute Unit) usage.
- By default, each Dataproc Serverless for Spark batch and interactive workload consumes a minimum of 12 DCUs for the duration of the workload: the driver uses 4 vCPUs and 16GB of RAM and consumes 4 DCUs, and each of the 2 executors uses 4 vCPUs and 16GB of RAM and consumes 4 DCUs
Data Compute Unit (DCU) pricing :
| Type | Price (hourly in USD) |
| DCU (Standard) | $ 0.07848 per hour |
| DCU (Premium) | $ 0.116412 per hour |
Shuffle Storage Pricing :
It is prorated and billed per second, with a 1-minute minimum charge for standard shuffle storage and a 5-minute minimum charge for Premium shuffle storage.
| Type | Price(monthly in USD) |
| Shuffle Storage (Standard) | $ 0.052 per GB |
| Shuffle Storage(premium) | $ 0.131 per GB |
Accelerator pricing :
| Type | Price(hourly in USD) |
| A100 40 GB | $ 4.605062 per hour |
| A100 80 GB | $ 6.165515 per hour |
Use GPU’s with Dataproc Serverless :
You can attach GPU accelerators to your Dataproc Serverless batch workloads to achieve the following results:
- Speed up the processing of large-scale data analytics workloads.
- Accelerate model training on large datasets using GPU machine learning libraries.
- Perform advanced data analytics, such as video or natural language processing.
Dataproc Serverless for Spark Auto scaling :
When you submit your Spark workload, Dataproc Serverless for Spark can dynamically scale workload resources, such as the number of executors, to run your workload efficiently. Dataproc Serverless autoscaling is the default behavior, and uses Spark dynamic resource allocation to determine whether, how, and when to scale your workload.
Dataproc Serverless security :
Dataproc Serverless workloads automatically implement the following security hardening measures:
- Spark RPC(Remote procedure call) authentication is Enabled.
- Spark RPC encryption is enabled.
- User runs the code as the non-root “spark” user within the containers.
How to Run a spark Batch workload :
- Open the Batch Page.
- Batch Info :
- Batch ID : Specify the an ID for your batch workload.This value must be 4-63 lowercase characters. Valid characters are
/[a-z][0-9]-/.
- Region : Select a region where your workload will run.
- Batch ID : Specify the an ID for your batch workload.This value must be 4-63 lowercase characters. Valid characters are
- Container :
- Batch Type : Spark
- Run time version: The default runtime version is selected. You can optionally specify a non-default run time versions.
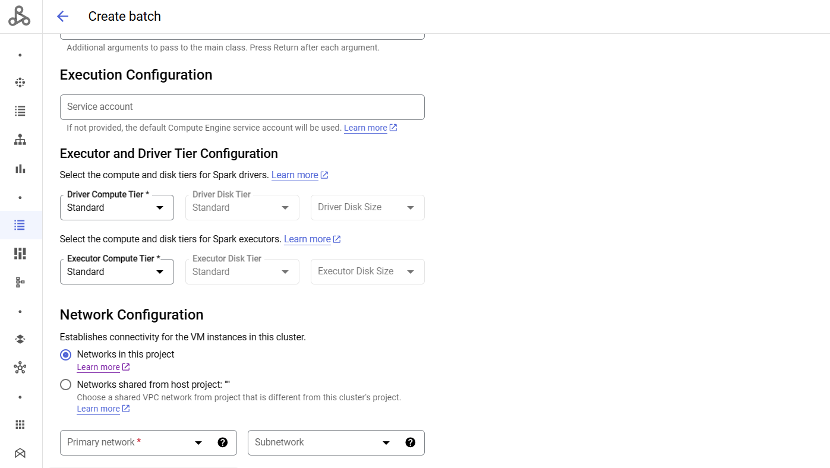
- Execution Configuration :
- You can Specify a service account to use to run your workload.if it is not specified then the work load will run under the default service account.
- Network Configuration :
- The VPC subnetwork that executes Dataproc Serverless for Spark workloads must be enabled for Private Google Access and meet the other requirements listed in Dataproc Serverless for Spark network configuration. The subnetwork list displays subnets in your selected network that are enabled for Private Google Access.
- Properties :
- Enter the
Key(property name) andValueof supported Spark properties to set on your Spark batch workload. Note: Unlike Dataproc on Compute Engine cluster properties, Dataproc Serverless for Spark workload properties don’t include aspark:prefix.
- Enter the
- Submit the Job.
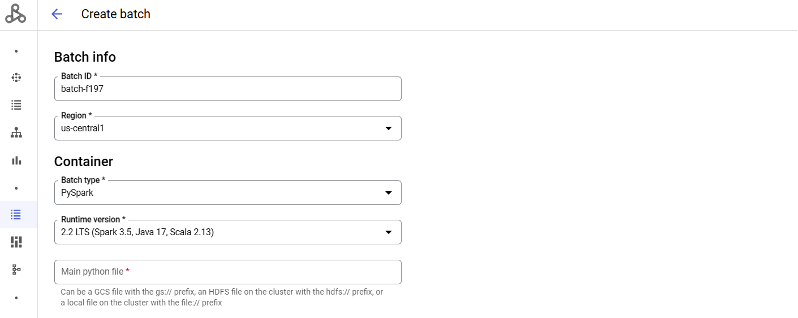
Attaching screenshot for reference
Submitting spark batch workload using gCloud CLI :
To submit a spark batch workload to compute , run the following gcloud CLI gcloud dataproc batches submit spark command in cloud shell gcloud dataproc batches submit –project che-dama-m2c-dev\ –region = asia-south1 \ –version = 2.1 \ pyspark = [Main script path ] \ –py-files = [add_dependenices]\ –subnet = [name_of_the_subnetwork] \ –-service-account = [service_account_name] \ –properties = spark.dynamicAllocation.executorAllocationRatio = 1,spark.dataproc.scaling.version=2,spark.executor.instances=2,spark.executor.cores=4,spark.executor.memory=8G,spark.driver.memory=4G,spark.driver.cores=2 \ –jars = [path_to_jar_files] \ –master-machine-type=n1-standard-4 \ –worker-machine-type=n1-standard-4 \ –num-workers=2 \ –num-worker-local-ssds=4 Note : Select the spark version – 2.1 as it supports all the dependencies and Enter the Highlighted fields as they are mandatory while submitting the job. 1. Region :a) Specify the REGION where your workload will run.2. Subnetwork:a) If the default network’s subnet for the region specified in the gcloud dataproc batches submit command is not enabled for Private Google Access, you must do one of the following:i. Enable default network’s subnet for the region for private google access.ii. Use the –subnet = [SUBNET_URI] flag in the command to specify a subnet that has private Google Access Enabled.You can run the gcloud compute networks describe [NETWORK_NAME] command to list the URIs of subnets in a network.
- –properties :
- Add this flag in the command to enter the supported spark properties that are required for your job.
gcloud dataproc batches submit \ properties=spark.sql.catalogImplementation=hive,spark.hive.metastore.uris=METASTORE_URI,spark.hive.metastore.warehouse.dir=WAREHOUSE_DIR> \
- –deps-bucket :
- You can add this flag to specify a Cloud Storage bucket where Dataproc Serverless will upload workload dependencies. This flag is only required if your batch workload reference files on your local machine
- RunTime verion :
- Use this verions Flag to specify the dataproc Serverless runtime version of the workload.
- Persistant History server :
- The Persistent History Server in Apache Spark is a component that allows you to persist and query historical information about completed Spark applications. It provides a web interface to view information such as completed application details, stages, tasks, and logs.
- The following command creates a PHS on a single-node Dataproc cluster. The PHS must be located in the region where you run batch workloads, and the Cloud Storage bucket-name must exist.
gcloud dataproc clusters create PHS_CLUSTER_NAME \ –region=REGION \ –single-node \ –enable-component-gateway \ –properties=spark:spark.history.fs.logDirectory=gs://bucket-name/phs/*/spark-job-history
- Submit a batch workload, specifying your running Persistent History Server
gcloud dataproc batches submit spark \ –region=REGION \ –jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ –class=org.apache.spark.examples.SparkPi \ –history-server-cluster=projects/project-id/regions/region/clusters/PHS-cluster-name \ Dataproc Serverless Templates : 1. Use dataproc serverless templates to quickly set up and run common spark batch workloads without writing the code. We can run the below following Dataproc Serverless Templates using Dataproc 1. Cloud Spanner to cloud Storage a) Attaching link for reference – https://cloud.google.com/dataproc-serverless/docs/templates/spanner-to-storage2. Cloud Storage to Big querya) Attaching link for reference – https://cloud.google.com/dataproc-serverless/docs/templates/storage-to-bigquery. 3. Cloud Storage to Cloud Spannera) Attaching link for reference : https://cloud.google.com/dataproc-serverless/docs/templates/storage-to-spanner?hl=en 4. Cloud Storage to Cloud Storage a) Attaching link for reference : https://cloud.google.com/dataproc-serverless/docs/templates/storage-to-storage?hl=en 5. Cloud Storage to JDBCa) Attaching link for reference : https://cloud.google.com/dataproc-serverless/docs/templates/storage-to-jdbc6. Hive to Bigquerya) Attaching link for reference : https://cloud.google.com/dataproc-serverless/docs/templates/hive-to-bigquery7. Hive to Cloud Storage a) Attaching link for reference : https://cloud.google.com/dataproc-serverless/docs/templates/hive-to-storage8. JDBC to Big Querya) Attaching link for reference : https://cloud.google.com/dataproc-serverless/docs/templates/jdbc-to-bigquery9. JDBC to Cloud Spannera) Attaching link for reference : https://cloud.google.com/dataproc-serverless/docs/templates/jdbc-to-spanner10. JDBC to Cloud Storagea) Attaching link for reference : https://cloud.google.com/dataproc-serverless/docs/templates/jdbc-to-storage11. JDBC to JDBC a) Attaching link for reference : https://cloud.google.com/dataproc-serverless/docs/templates/jdbc-to-jdbc12. Pub/Sub to Cloud Storagea) Attaching link for reference : https://cloud.google.com/dataproc-serverless/docs/templates/pubsub-to-storage
Big query connector with Spark using CLI
Use the spark-bigquery-connector with Apache Spark to read and write data from and to BigQuery. gcloud dataproc batches submit pyspark \ –region=region \–jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.13-version.jar \ Dataproc serverless Permissions : Dataproc serverless permissions allow users, including service accounts , to perform actions on Dataproc serverless resources. The following tables list the permissions necessary to call dataproc serverless API’s1. Batch permissions2. Session permissions3. Session runtime permissions4. Operation permissions Dataproc serverless roles : You grant roles to users or groups to allow them to perform actions on the Dataproc Serverless resources in your project.
| Role ID | Permissions |
| roles/dataproc.admin | dataproc.batches.cancel dataproc.batches.create dataproc.batches.delete dataproc.batches.get dataproc.batches.list dataproc.batches.cancel dataproc.sessions.create dataproc.sessions.delete dataproc.sessions.get dataproc.sessions.list dataproc.sessions.terminate dataproc.sessionTemplates.create dataproc.sessionTemplates.delete dataproc.sessionTemplates.get dataproc.sessionTemplates.list dataproc.sessionTemplates.update |
| roles/dataproc.editor | dataproc.batches.cancel dataproc.batches.create dataproc.batches.delete dataproc.batches.get dataproc.batches.list dataproc.sessions.create dataproc.sessions.delete dataproc.sessions.get dataproc.sessions.list dataproc.sessions.terminate dataproc.sessionTemplates.create dataproc.sessionTemplates.delete dataproc.sessionTemplates.get dataproc.sessionTemplates.list dataproc.sessionTemplates.update |
| roles/dataproc.viewer | dataproc.batches.get dataproc.batches.list dataproc.sessions.get dataproc.sessions.list dataproc.sessionTemplates.get dataproc.sessionTemplates.list |
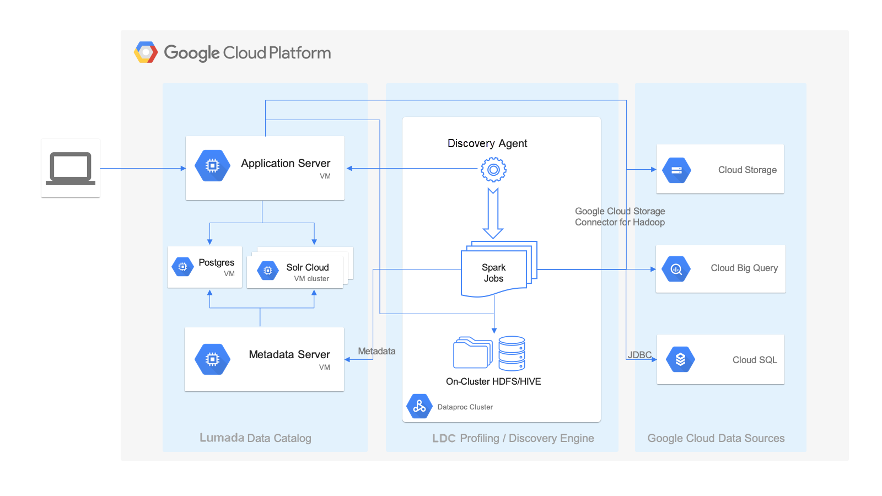
The below flow diagram shows the complete dataflow and how the data process from the ingestion to getting desired output