Mainframe modernization refers to the process of modernizing and converting legacy mainframe applications to make them more efficient, cost-effective, and compatible with contemporary technologies. In today’s industry, mainframe modernization plays a crucial role in transferring mainframes to cloud platforms.
Why should firms opt the Mainframe modernization?
Many firms still rely on mainframe systems for important business activities, but these systems are often old, expensive to maintain, and difficult to connect with modern software and hardware. Modernization tries to overcome these difficulties while keeping mainframe applications core features.
The modules involved in mainframe modernization are detailed below.
Application code
UI
Database
Middleware
Infrastructure
Modernization Approaches:
There are three methods for migrating application code.
Re-Factoring
Re-Hosting.
Re-Platform.
Re-Factoring
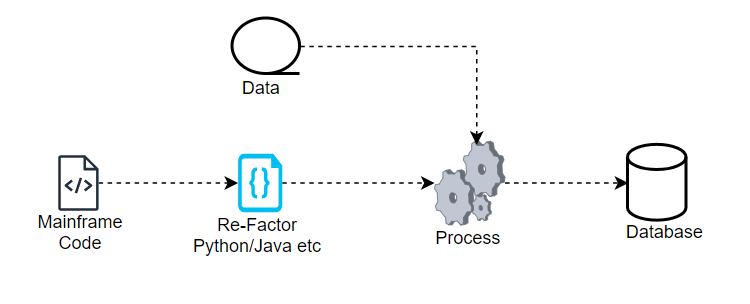
Re-factoring is the technique of redesigning existing computer code without affecting its exterior behaviour. The basic purpose of refactoring is to improve the underlying structure of the code, making it easier to understand, maintain, and extend without affecting its observable functioning. This method is typically used with legacy code or code that has grown difficult to manage.
Mainframe modernization [Re-Factor process]
The mainframe application code will be rewritten in Java, .Net, C, Python, and other languages during the re-factoring process. This will be accomplished in two ways.
Automation
Manual
Automation:
Certain tools are currently available on the market. These tools can convert the code completely, however there are certain downsides.
Can’t optimize the code.
Tools cost.
Only can convert into selected languages like Java, .Net, etc.,
Only supports selected cloud platforms.
Manual:
In this manual, mainframe application code can be converted into any cloud platform-supported language. With optimization, conversion can reach 100%, however there are some disadvantages.
Deployment timing will be 2 years. [Depending on the various factors]
Resource availability.
Benefits of Re-factoring:
Improves the code quality.
Reduce support cost.
Maintain a stable code base.
Reusability of software components
Challenges and Considerations:
Challenges:
Maintaining functionality
Managing dependencies
Testing
Communication
Balancing short-term and long-term goals
Considerations:
Understanding the code base
Define clear objectives.
Ensure sufficient test coverage.
Use incremental refactoring.
Maintain version control.
Monitor Performance
Tools:
Blu Age
Fujitsu NetCOBOL
Micro Focus Visual COBOL
Astadia Code Turn
Re-Hosting
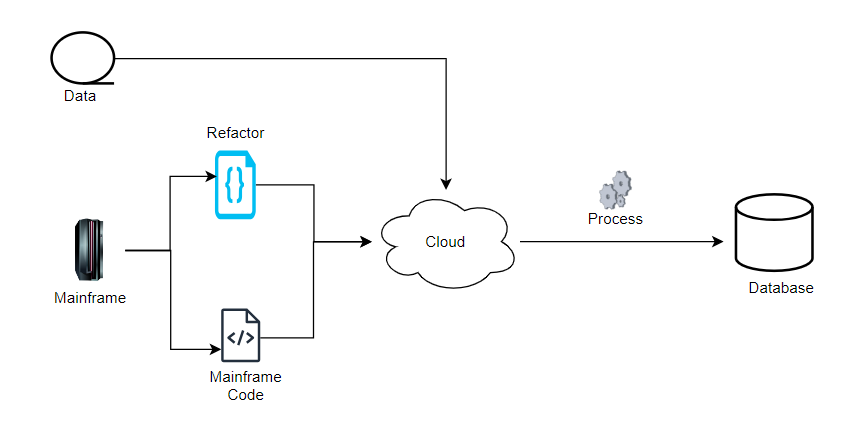
Re-hosting, often known as lift-and-shift, is a modernization strategy that involves relocating an application or system from its existing environment to a new one without significantly altering the underlying code or design. The purpose of re-hosting is to reap the benefits of a new infrastructure, such as the cloud, while reducing the time and risk involved with code changes.
Mainframe modernization [Re-Host process]
Benefits of Re-hosting:
Minimal or no changes to the application code
Reduce complexity and risk associated with migration process.
Challenges and Considerations:
Challenges:
Data Migration issues
Cost implications
Compatibility issues
Security concerns
Lack of documentation
Considerations:
Assessment and Planning
Infrastructure
Compatibility and Compliance
Data migration
Performance optimization
Testing, Monitoring, and Documentation
Tools:
Micro Focus COBOL
Astadia Code Turn
TMAXSOFT
Re-Platform
Re-Platform, often known as lift-and-reshape. This cloud migration tactic focuses on refining a legacy system to function effectively within a cloud setting, all without needing to completely overhaul its fundamental structure.
At its core, a web service is a versatile software element facilitating interoperable machine-to-machine interactions across networks. These interactions are carried out using XML-based information exchange systems over the Internet, enabling seamless application-to-application communication using collection of standards or protocols.
Web Services in Simple Terms
In simpler terms, a web service encompasses fundamental functions:
Operates on a server system.
Connects over the internet or intranet networks.
Utilizes standardized XML messaging for communication.
Compatible with any operating system or programming language
Self-describes through standard XML language.
Discoverable through a straightforward location method
How Web Services Work
The functionality of web services is supported by key components, including:
Service Provider: Creates and offers specific services over the internet or a network. They publish the service, making it accessible to others who want to use it.
UDDI (Universal Description, Discovery, and Integration): Acts as a digital directory for web services, allowing service providers to list their services and providing a way for service consumers to discover and locate these services based on their descriptions and specifications.
WSDL (Web Services Description Language): A standardized language used to describe the interface and functionality of a web service. It provides a clear and structured way for service consumers to understand how to interact with a particular web service.
Web Service: A software component or application that can be accessed over the internet using standardized protocols. It allows different systems to communicate and share data or functionality, often over HTTP.
Service Consumer: An application that makes use of a web service. It sends requests to the service provider to access specific functions or retrieve data offered by the service.
Web Services Life Cycle
About WSDL
Imagine searching for a restaurant without knowing its location or menu. Similarly, WSDL (Web Services Description Language) acts as a map for web services. It guides the client to the service’s location and functionality, providing essential information on how to connect and interact with the web service.
Can you use a web service if you don’t know where it is? No, the client needs to know the location.
What else does the client need to know? The client needs to understand what the web service does.
How does the client learn these things? Through WSDL (Web Services Description Language).
What’s WSDL? WSDL is like a manual in XML format, detailing the web service’s location and capabilities.
WSDL Elements
WSDL includes elements such as <message>, defining data pieces for web service operations, <portType>, listing the operations offered, and <binding>, specifying communication details.
Web Service Types
SOAP (Simple Object Access Protocol)
SOAP operates by transferring XML data as SOAP Messages, consisting of an Envelope element, a header, a body, and an optional Fault element for reporting errors.
SOAP Message Components
The Envelope Element:
Description: The Envelope is like a container for the SOAP message. It wraps everything in a SOAP message.
Role: It tells the recipient that this is a SOAP message.
The Header Element:
Description: The Header is like a special instruction section. It can contain extra information that helps with processing the message.
Role: It provides additional details or instructions for the message.
The Body Element:
Description: The Body holds the main content of the message. It contains the actual data or information being sent.
Role: It carries the essential payload of the message.
The Fault Element (Optional):
Description: The Fault element is used to report errors if something goes wrong with the message.
Role: It’s optional but helps in communicating issues or exceptions.
RESTful Web Services
REST (Representational State Transfer) is a scalable way to share data between applications over the web. It employs HTTP and involves resources, request verbs, request headers, request and response bodies, and response status codes.
REST Message Components
Resources:
Resources are like pieces of information or data, such as an employee record or a product listing.
Each resource is identified by a unique URL, like http://application.url.com/employee/1234, where “/employee/1234” represents a specific employee’s record.
Request Verbs:
Request verbs are the actions you want to perform on resources.
The most common verb is GET, which is used to read data from a resource.
Other verbs include POST, PUT, DELETE.
Request Headers:
Request headers are additional instructions sent with your request.
They provide extra details about how the request should be handled.
For example, headers might specify the format of the response or include authentication information.
Request Body:
The request body carries data sent with POST or PUT requests. It contains the information you want to add or modify in the resource.
For instance, when adding a new employee, the request body would include their details, like name and contact information.
Response Body:
The response body is where the server provides the requested data.
If you’re GETting employee details, the response body might contain that information in a format like XML or JSON.
It’s the heart of the server’s response to your request.
Response Status Codes:
Response status codes are like short messages from the server. They tell you how the server handled your request.
For example, a 200 status code means “OK” and indicates a successful operation, while a 404 code means “Not Found” and suggests the requested resource doesn’t exist.
CICS Web Services
Introduction to CICS Web Services
CICS TS Server introduces a Web Service Support component enabling the transformation of traditional CICS programs into message-driven ‘services.’ This transformation allows these programs to be accessible to ‘service consumers’ within an enterprise.
Integration with Modern Technologies
CICS Web Services serve as a bridge between traditional mainframe systems and modern web-based applications. This integration facilitates the participation of mainframe applications in the world of web services, simplifying connections with other systems.
Exposing Mainframe Capabilities
CICS Web Services enable the exposure of functionalities and data stored in mainframe applications as web services. This means that applications, irrespective of their platform or technology, can access and utilize mainframe resources.
Standard Protocols
CICS Web Services typically use standard web protocols like HTTP and HTTPS for communication, ensuring interoperability and compatibility with a wide range of systems and programming languages.
Scalability and Accessibility
By enabling mainframes to provide web services, organizations can leverage robust and scalable mainframe resources to handle web-based workloads. This extension enhances the lifespan and value of existing mainframe investments.
Modernization
CICS Web Services play a pivotal role in modernizing legacy mainframe systems. They facilitate the gradual transition to more contemporary architectures and interfaces while leveraging existing mainframe assets.
CICS Web Services Flow
CICS Web Services Components
CICS Web Services involve components such as Service Provider, UDDI, WSDL, Web Service, and Service Consumer, working together to create a seamless web service environment.
CICS Set Up for Web Services
Setting up CICS for web services involves creating TCPIPSERVICE and PIPELINE resource definitions, installing them, generating the wsbind file using WSDL files, and publishing the WSDL files to service requester clients.
In conclusion, understanding web services, their types, integration with CICS, and the necessary configurations opens up a world of possibilities for seamless and modernized communication in today’s technologically diverse landscape.
A Single Page Application is a web application that loads a single HTML page and dynamically updates the content as the user interacts with the application. Instead of requesting a new page from the server each time the user interacts with the application, a SPA loads all necessary resources and content up front and uses client-side rendering to update the page dynamically. SPAs are important because they provide a faster and more responsive user experience compared to traditional web applications. By loading all necessary resources up front, SPAs reduce the amount of time it takes for pages to load and content to appear on the screen. SPAs also allow for more seamless interactions between the user and the application, resulting in a more natural and intuitive user experience. The design pattern used in SPAs is based on client-side rendering, where the majority of the application logic and rendering occurs in the user’s browser instead of on the server. This allows for faster and more efficient processing of user interactions, resulting in a smoother user experience.
A Single page application is that doesn’t need to reload the page during its use and works within a browser. SPA used daily: Facebook, GitHub and Gmail
Advantages:
SPA are fast as most of the resources including html, css and Scripts are loaded once and the only data is transmitted back and forth.
Quick Loading Time: Page loads quicker than traditional web applications, as it only has to load a page at the first request.
Seamless User Experience: Users do not have to watch a new page load as only content changes.
Better Caching
Easier Maintenance
Smooth Navigation
Less Complex Implementation
When to use:
When a user looking to develop a application which handles smaller data volume and if application requires high level of interactivity and dynamic content updates.
Working of SPAs: The working of a SPA involves the following steps:
The initial HTML, CSS, and JavaScript files are loaded into the browser when the user first accesses the application.
As the user interacts with the application, the browser sends requests to the server for data, which is returned as JSON or XML.
The application uses JavaScript to parse the data and dynamically update the page without requiring a full page reload.
The application uses client-side routing to manage the display of different views and components within the application.
Developing a Single-Page Application (SPA) with Angular and the MEAN stack (MongoDB, Express.js, Angular, and Node.js) is a popular choice for building modern web applications. Here’s a step-by-step guide to help you get started:
Setup Your Development Environment:
To build SPA you will need a basic understanding of the following
Typescript
HTML
CSS
Angular CLI
Before you begin, make sure you have Node.js and npm (Node Package Manager) installed on your system. You’ll also need Angular CLI for creating and managing Angular applications. MongoDB should be installed and running for your backend.
Open a command prompt or terminal window and run the following to install the Angular CLI
Npm install -g@angular/cli
Once the Angular CLI is installed , create a new angular project by running the following command.
Ng new spa
This will create a new angular project in a directory named spa.
Create a new component by running the following command
Ng g c home
This will create a new component named home in src/app directory
Add some content in the html file and define the route in app-routing-module.ts.
To start the development server use the following command
Ng serve
This will start the development server and launch the application in your default web browser.
Create the Backend with Node.js and Express:
Create a new directory for your backend, and within that directory, run the following commands:
Go to the directory where you want to create the project
Initialize the Node project using
Npm init
Follow the prompts to configure your Node.js application. Then, install Express and other required packages:
Set up your Express server and routes for API endpoints
Install express using npm
Npm install express
Create a file index.js as entry point to the backend
Install body-parser using npm
Npm install body-parser
Add the code in index.js and establish the database connection.
Now start the backend server using
Node index.js
Define your routes and port and once you start application open browser and try to router to
Ensure MongoDB is installed and running on your system. You may need to create a new database for your application.
Create Models and Schemas:
Define your data models and schemas using Mongoose, a popular library for working with MongoDB in Node.js. This step involves defining how your data will be structured in the database.
Build the API Endpoints:
Create routes for your API endpoints to handle CRUD (Create, Read, Update, Delete) operations. Use the Express router to organize your routes.
Implement Authentication (Optional):
If your application requires user authentication, consider using libraries like Passport.js for handling user authentication and JWT (JSON Web Tokens) for secure user sessions.
Integrate Angular with the Backend:
In your Angular application, you can use the HttpClient module to make HTTP requests to your Express API. Create services in Angular to encapsulate the HTTP calls and interact with the backend.
Create the Angular Components:
Build the components of your SPA. These components will define the structure and functionality of your application, such as user interfaces, views, and forms.
Implement Routing in Angular:
Configure Angular’s routing to enable navigation between different views or components in your SPA. You can use the Angular Router module for this purpose.
Connect the Backend and Frontend:
Ensure that your Angular application can communicate with your Express API by making HTTP requests to the defined endpoints.
Testing:
Test your application thoroughly, both on the frontend and backend. You can use tools like Jasmine and Karma for Angular unit testing and tools like Postman for testing API endpoints.
Deployment:
When you are satisfied with your application, deploy it. You can deploy your MEAN stack application to platforms like Heroku, AWS, or any other hosting service of your choice.
Continuous Integration and Deployment (CI/CD):
Consider setting up a CI/CD pipeline to automate the deployment process, ensuring that your application is always up to date.
Monitoring and Maintenance:
After deployment, monitor your application’s performance and security. Regularly update dependencies and maintain your codebase.
This is a high-level overview of the steps involved in developing a SPA with Angular and the MEAN stack. Keep in mind that building a production-ready application may require more advanced features and optimizations. Be sure to consult the documentation for Angular, Express, and MongoDB, as well as best practices in web development, for more in-depth information on each step.
Data Build Tool, commonly known as dbt, has gained recently significant popularity in the realm of data pipelines and Intrigued by its popularity. The Data Build Tool (DBT) is an open-source command-line tool for transforming and managing data within a data warehouse. dbt is primarily focused on the transformation layer of the data pipeline and is not involved in the extraction and loading of data. DBT is commonly used in conjunction with SQL-based databases and data warehouses such as Snowflake, Big Query, and Redshift. In this we can build reusable SQL code and define dependencies between different transformations. This approach greatly enhances data consistency, maintainability, and scalability, making it an asset in the data engineering toolkit.
Advantages of DBT: –
Open Source: It is freely available and accessible to DBT Core users.
Modularity: DBT promotes modular and reusable code, enabling the creation of consistent, maintainable, and scalable data transformations.
Incremental Builds: It supports incremental data builds, allowing you to process only the data that has changed, reducing processing time and resource usage.
Version Control: DBT can be integrated with version control systems like Git, facilitating collaboration and version tracking for your data transformation code.
Testing Framework: DBT provides a robust testing framework to verify the quality of your data transformations, catching issues early in the pipeline.
Components of DBT: –
We have two components in DBT. They are:
DBT Core
DBT Cloud
DBT Core:
With DBT Core, you can define and manage data transformations using SQL-based models, run tests to ensure data quality, and document your work. It operates through a command-line interface (CLI), making it easy for data professionals to develop, test, and deploy data transformations while following industry-standard practices. DBT Core is widely used in the data engineering and analytics community to streamline data transformation processes and ensure data consistency and reliability.
Key Features of DBT Core:
SQL Based Transformation
Incremental Builds
Tests and Documentation
DBT Cloud:
DBT Cloud is a cloud-based platform that offers a speedy and dependable method for deploying code. It features a unified web-based user interface for scheduling tasks and investigating data models.
The DBT Cloud application comprises two types of components: static and dynamic. Static components are consistently operational, ensuring the availability of critical DBT Cloud functions like the DBT Cloud web application. In contrast, dynamic components are generated on-the-fly to manage tasks such as background jobs or handling requests to use the integrated development environment (IDE).
Key Features of DBT Cloud: –
Scheduling Automation
Monitoring
Alerting
Differences Between DBT Core and DBT Cloud: –
Feature
DBT Core
DBT Cloud
Deployment Environment
DBT Core is typically used in a local development environment. You install and run it on your local machine or on your organization’s infrastructure.
DBT Cloud is a cloud-based platform and is hosted in the cloud. It provides a managed environment for running DBT projects without the need to manage infrastructure.
Scheduling
DBT Core does not natively provide scheduling capabilities. You would need to use external tools or scripts to schedule DBT runs if needed.
DBT Cloud includes built-in scheduling features, allowing you to automate the execution of DBT models and transformations on a defined schedule.
Monitoring and Alerts
DBT Core may require third-party tools for monitoring and alerting on data transformation issues.
DBT Cloud includes monitoring tools and alerts to notify you of problems in your data transformation pipelines.
Security and Compliance
Security features in DBT Core depend on how it is configured and secured within your own infrastructure.
DBT Cloud provides security features to protect your data and ensure compliance with data privacy regulations.
Scalability
DBT Core can be used for both small-scale and large-scale data transformation tasks, but you need to manage the scaling yourself.
DBT Cloud is designed to scale easily, making it well-suited for larger teams and more complex data operations.
Orchestration
DBT Core does not include built-in orchestration capabilities. You need to manage the execution order of models and transformations manually
DBT Cloud provides orchestration features to define and automate the sequence of data transformations, ensuring they run in the correct order.
Built-in Folders in DBT: –
analyses
dbt_packages
logs
macros
models
seeds
snapshots
target
tests
dbt_project.yml
dbt_project.yml: –
The dbt_project.yml file is a central configuration file that defines various settings and properties for a DBT project. This file is located in the root directory of your DBT project and is used to customize how DBT runs, connects to your data warehouse, and organizes your project.
This file is crucial for configuring your DBT project and defining how it interacts with your data sources and the target data warehouse. It helps ensure that your data transformation processes are well-organized, maintainable, and can be easily integrated into your data pipeline.
Analyses: –
Analyses refer to SQL scripts or queries that are used for ad-hoc analysis, data exploration, or documentation purposes. Analyses are a way to write SQL code in a structured and version-controlled manner, making it easier to collaborate with other team members and ensuring that your SQL code is managed alongside your data transformations. Analyses help you organize and document your SQL code for data exploration, reporting, and quality validation within your DBT project.
dbt_packages.yml: –
The dbt_packages.yml file is a configuration file used to specify external packages that you want to include in your DBT project. These packages can be thought of as collections of DBT code and assets that are developed and maintained separately from your project but can be easily integrated. It is used to help manage and share reusable DBT code, macros, models, and other assets across different DBT projects.
When we want to use more packages in our project, we need to create a new file with the name of packages.yml in our project and mention the package name and version like below. When you run dbt deps, DBT will resolve and fetch the specified packages (including their models, macros, and other assets) and integrate them into your project. This allows you to reuse and share code and best practices across different DBT projects, making it easier to collaborate and maintain consistency.
Logs: –
These logs provide detailed information about the tasks performed, including data transformations, tests, and analysis runs, making them essential for monitoring and troubleshooting your DBT projects.
Overall, logs in DBT play a crucial role in helping you monitor the health and performance of your data transformation processes and in diagnosing and troubleshooting issues that may arise during the development and execution of your DBT projects.
Macros: –
Macros are reusable pieces of SQL code that you can use to perform various tasks, such as custom transformations, calculations, and data validation. These are analogous to “functions” in other programming languages and are extremely useful if you find yourself repeating code across multiple models. Macros are defined in .sql files, typically in your macro’s directory.
Benefits and key components of Macros: –
Code Reusability
Maintainability
Code consistency and modularity
Abstraction
Models: –
Models are the basic building block of our business logic. In models we can create tables and views to transform the raw data into structured data by writing SQL Queries. It promotes Code modularity and reusability of the SQL Code. It follows dependency management. i.e. To execute the models. It supports incremental data builds and updates only updated data.
Materialization: –
There are four built-in materializations too, how your models can be stored and managed in Datawarehouse. They are:
Views
Tables
Incremental
Ephemeral
View Materialization: –
When using the view materialization, your model is rebuilt as a view on each run.
Pros: No additional data is stored, views on top of source data will always have the latest records in them.
Cons: Views that perform a significant transformation, or are stacked on top of other views, are slow to query.
Table materialization: –
When using the table materialization, your model is rebuilt as a table on each run.
Pros: Tables are fast to query.
Cons: New records of underlying source data are not automatically added to the table.
Incremental Materialization: –
Models allow dbt to insert or update records into a table since the last time that dbt was run.
Pros: You can significantly reduce the build time by just transforming new records.
Cons: Incremental models require extra configuration and are an advanced usage of dbt.
Ephemeral: –
It is Very much virtual materialization. Ephemeral models are not directly built into the Datawarehouse. It hides the view/table when we use dbt run command.
Pros: Can help your Datawarehouse by reducing clutter.
Cons: For the first time you need to drop view/table manually from the snowflake.
Seeds: –
Seeds are CSV files in your dbt project (typically in seeds directory). Seeds are local files that you load into your Datawarehouse using dbt seed. Seeds can be referenced in downstream models the same way as referencing models – by using ref function. Seeds are best suited to static data which changes infrequently.
Command to Upload csv file in seed:
curl file:/// path of file -o seeds/filename.csv
Note: csv files must and should have header or else the first record it considers as header.
Sources: –
Sources is an abstract layer on the top of your input tables (raw tables) and the data is more structured. Sources make it possible to name and describe the data loaded into your warehouse by your Extract and Load tools.
Note:select from source tables in your models using the {{source() }} function, helping define the lineage of your data.
Snapshots: –
In dbt (Data Build Tool), “snapshots” are a powerful feature used to capture historical versions of your data in a data warehouse They are particularly useful when you need to track changes to your data over time, such as historical records of customer information, product prices. It implements the scd type 2.
Advantages of Snapshots: –
1.See the Past: Imagine you have data, like prices or customer info. Snapshots let you look back in time and see how that data looked on a specific date. It’s like looking at a history book for your data.
2.Spot Changes: You can easily spot when something changes in your data. For example, you can see when a product’s price went up or when a customer’s address was updated.
3.Fix Mistakes: If there’s a problem with your data, you can use snapshots to figure out when the problem started and how to fix it.
4.Stay Compliant: For some businesses, keeping old data is a legal requirement. Snapshots done this.
Strategies of Snapshots: –
Timestamp
Check
Timestamp: –
The timestamp strategy uses an updated_at field to determine if a row has changed. If the configured updated_at column for a row is more recent than the last time the snapshot ran, then dbt will invalidate the old record and record the new one. If the timestamps are unchanged, then dbt will not take any action.
Check: –
The check strategy is useful for tables which do not have a reliable updated_at column. This strategy works by comparing a list of columns between their current and historical values. If any of these columns have changed, then dbt will invalidate the old record and record the new one. If the column values are identical, then dbt will not take any action.
Disadvantages of Snapshots: –
Storage cost become significant
Performance Impact
Limit the transformation amount
Tests: –
Tests are a critical component of ensuring the quality, correctness, and reliability of data transformations and play a crucial role in catching data issues and discrepancies. DBT allows you to define and run tests that validate the output of your SQL transformations against expected conditions.
Benefits of Tests: –
Data Quality
Collaboration and Maintenance
Documentation
Types of Tests: –
Singular Tests
Generic Tests
Singular Tests: –
Singular tests are very focused, written as typical SQL statements, and stored in SQL files typically in tests directory.
We can use Jinja templates (ref, source) in tests and it returns failed records.
In Singular Tests we must go through negative testing.
Generic Tests: –
Generic tests are written and stored in YML files, with parameterized queries that can be used across different dbt models. And they can be used over again and again. The main Components of generic tests:
Unique
Not null
Relationship
Accepted Values
Target: –
The “Target” folder is a directory where DBT stores the compiled SQL code and materialized views (tables or other objects) that result from running the DBT transformations. The exact structure and contents of the target directory may vary depending on your data warehouse and the DBT project’s configuration. The location of the target directory is typically specified in your dbt_project.yml configuration file using the target-path setting. By default, it’s located in the root directory of your DBT project.
Hooks in DBT: –
There are some repeatable actions that we want to take either at start or end of our run or before and after at each step, so for this process Dbt introduces the hooks process. Hooks are snippets of SQL that are executed at different times.
Types of Hooks:
Pre-hooks:
Pre-hooks are executed before specific DBT commands or tasks. For example, you can define a pre-hook to run custom code before executing a DBT model.
Post-hooks:
Post-hooks are executed after specific DBT commands or tasks. You can use post-hooks to perform actions after a model is built or a DBT run is completed. on-run-start Hook:
The on-run-start hook is executed at the beginning of a DBT run, before any models are processed.
on-run-end Hook:
The on-run-end hook is executed at the end of a DBT run, after all models have been processed, tests have been run, and other run tasks are completed.
All the above are the built in files and features in our DBT project to perform transformation of the data. After completing transformation, we can be able to generate the documentation. And this Documentation which contains explanations, and descriptions to your DBT project, models, columns, tests, and other components. It helps make your data transformation code more understandable, shareable, and self-documenting, making it easier for your team to work with your project.
Overall, the Documentation in DBT is a valuable feature for enhancing the maintainability and collaborative aspects of your data transformation projects. It ensures that the business logic and data meanings are well-documented and accessible to everyone involved in the project.
Validations in dbt refer to the process of checking the quality, integrity, and correctness of transformed data using SQL queries. These checks help ensure that the data produced by your DBT models adheres to business rules, data quality standards, and other criteria. DBT allows you to automate these checks, report issues, and take action based on the validation results.
Benefits of Tests: –
Data Quality
Collaboration and Maintenance
Documentation
Types of Tests: –
Generic Tests
Singular Tests
Singular Test: –
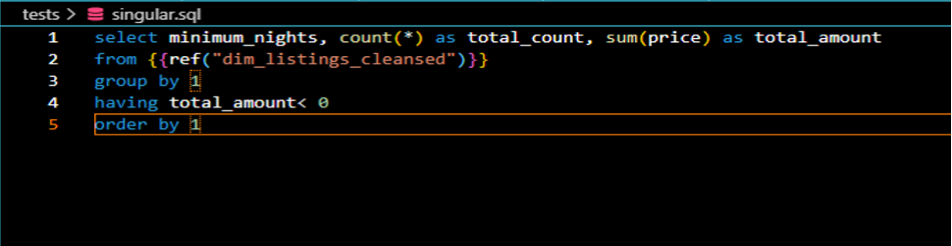
Singular tests are a type of test in dbt that involves writing a SQL query, which if it returns any rows, would represent a failing test. They are one-off assertions usable for a single purpose. They are defined in .SQL files, typically in the test directory. They can include jinja in the SQL query. An example of a singular test is to check if there are any negative or null values in a table. To create a singular test, you can write a SQL query that returns failing rows and save it in a. sql file within your test directory. It will be executed by the dbt test command.
Test Selection Examples: –
dbt test —- Checks all the tests in project
dbt test –select test_type:singular # checks only singular tests
dbt test –select test_type:generic # checks only generic tests
dbt test –select test_name (ex: dbt test –select dim_listings) # to test single test
dbt test –select config.materialized:table # to test specific materializations
dbt test –select config.materialized:seed # to test seeds
dbt test –select config.materialized:snapshot # to test snapshots
Schema.yml In dbt (data build tool), the schema.yml file is used to define the structure and configuration of your data models. It includes information such as model descriptions, column descriptions and tests (Generic test, dbt package related tests like dbt_utils, dbt_expectations)
Advantages: –
Used to define the structure and configuration of your data models.
It includes information such as model descriptions, column descriptions and tests
Makes it easier to maintain your models and keep them up to date.
Generic Tests: –
Generic tests are written and stored in YML files, with parameterized queries that can be used across different DBT models. And they can be used over again and again. The main Components of generic tests:
Unique
Not null
Relationship
Accepted Values
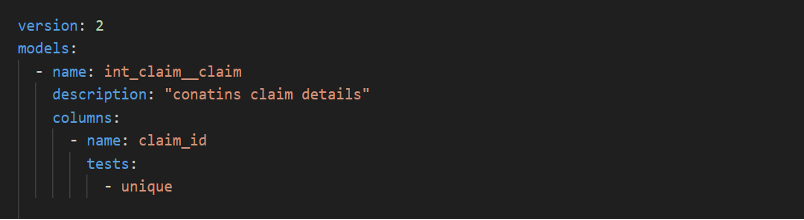
Unique: –
unique is a test to verify that every value in a column contains unique values.
e.g.
In the above example it checks if the claim_id columns contain unique values or not. If not, test will be failed otherwise pass.
Not Null: –
The Not Null test ensures that a column in a model doesn’t contain any null values.
e.g:
In the above example it checks if the versions column to see if it contains any null values. If no nulls populated test will be Passed otherwise Failed.
Accepted Values: –
This test is used to validate whether a set of values within a column is present.
In the above example the payee number should accept either 0 or 1. Other than these values test will be Failed.
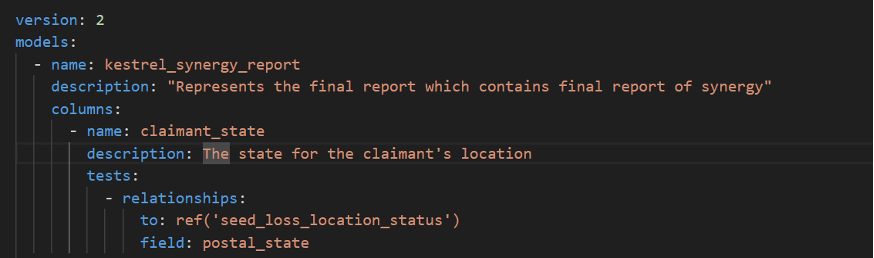
Relationship: –
A relationship typically involves ensuring that a foreign key relationship between two models is maintained.
e.g:
Kestrel_synergy_report model’s claimant_state column tests a relationship with postal_state in
Seed_loss_location_status for data consistency. If not, it will be Failed.
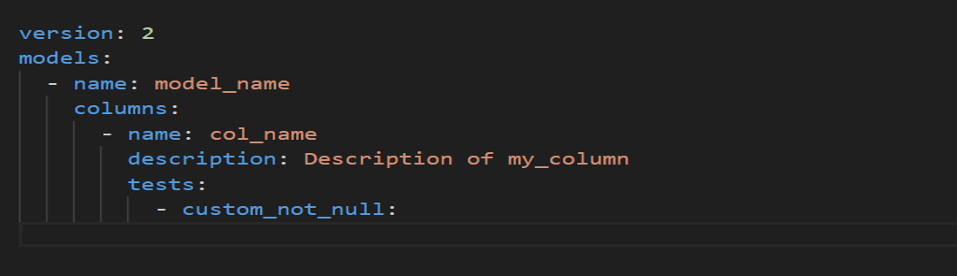
Custom Generic Tests: –
In dbt, it is also possible to define your own custom generic tests. This may be useful when you find yourself creating similar Singular tests. A custom generic test is essentially the same as a dbt macro which has at least a model as a parameter, and optionally column name. if the test will apply to a column. Once the generic test is defined, it can be applied many times just like the generic tests shipped with dbt Core. It is also possible to pass additional parameters to a custom generic test.
We create these tests within macros folder.
To run this above code, we have to define it in schema.yml and use dbt test command in terminal.
Advanced Tests in DBT: –
DBT comes built with a handful of built-in generic tests and even more tests are available from community DBT packages. This dbt package contains macros that can be (re)used across dbt projects.
We can directly use this test cases in schema.yml for any required models.
dbt utils
dbt expectations
dbt utils: –
The dbt-utils package is a collection of macros that enhances the dbt experience by offering a suite of utility macros. It is designed to tackle common SQL modeling patterns, streaming complex operations, allowing users to focus on data transformation rather than the intricacies of SQL. Dbt does provide some utility functions and macros that can be used within your dbt projects.
The dbt_utils package include 16 generic tests including:
not_accepted_values
equal_rowcount
fewer_rows_than
You can find detailed information on all the dbt-utils generics tests using given reference link
You can install the package by including the following in your packages. yml file.
You can then run dbt deps in gitbash to install the package. dbt-expectations.
Below are the sample tests from dbt_utils:
Equal row count: –
Check that two relations (Models) have the same number of rows.
Replace model, compare model with existing models in your dbt.
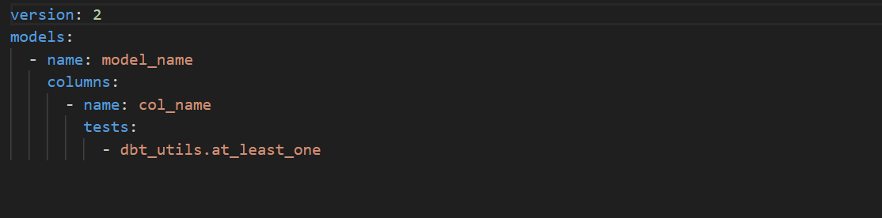
at_least_one: –
Asserts that a column has at least one value.
Replace model_name with your Model (Table Name), col_name with your Column Name.
dbt expectations: –
dbt-expectations are an extension package for dbt that allows users to deploy data quality tests in their data warehouse directly from dbt. It is inspired by the Great Expectations package for Python. Data quality is an important aspect of data governance, and dbt-expectations help to flag anomalies or quality issues in data.
Tests in dbt-expectations are divided into seven categories encompassing a total of 62 generic dbt tests:
Table shape (15 generic dbt tests)
Missing values, unique values, and types (6 generic dbt tests)
Sets and ranges (5 generic dbt tests)
String matching (10 generic dbt tests)
Aggregate functions (17 generic dbt tests)
Multi-column (6 generic dbt tests)
Distributional functions (3 generic dbt tests)
You can find detailed information on all the dbt-expectations generics tests using given reference link
You can install dbt-expectations by adding the following code to your packages.yml file:
You can then run dbt deps in gitbash to install the package. dbt-expectations.
Below are the sample tests from dbt_expectations
Expect_column_value_lengths_to_equal :-
Expect column entries to be strings with length equal to the provided value.
Replace model_name with your Model (Table Name), col_name with your Column Name.
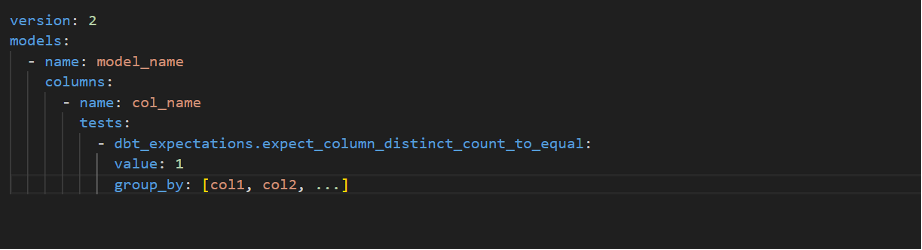
Expect Column Distinct count to Equal: –
Expect the number of distinct column values to be equal to a given value.
Replace model_name with your Model (Table Name), col_name , col1… with your Column Names.
Expect Column values to be in set: –
Expect each column value to be in a given set.
Replace model_name with your Model (Table Name), col_name with your Column Name.
Tags: –
In dbt, tags can be applied to tests to help organize and categorize them. Tags provide a way to label or annotate tests based on specific criteria, and you can use these tags for various purposes, such as filtering or grouping tests when running dbt commands.
Commands to run Tags: –
dbt test –select tag: my_tag (e.g. dbt test –select tag: a)
dbt test –select tag: my_tag –exclude tag:other_tag
(e.g. – dbt test – select tag: a –exclude tag:b)
Severity: –
In dbt, severity is a configuration option that allows you to set the severity of test results. By default, tests return an error if they fail. However, you can configure tests to return warnings instead of errors, or to make the test status conditional on the number of failures returned.
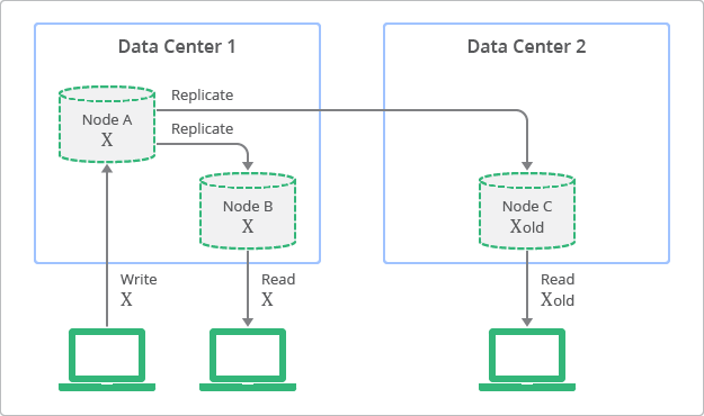
Eventual Consistency: As the name suggests, eventual consistency means that changes to the value of a data item will eventually propagate to all replicas, but there is a lag, and during this lag, the replicas might return stale data. A scenario where changes in Database 1 take a minute to replicate to Databases 2 and 3 is an example of eventual consistency.
Suppose you have a blog post counter. If you increment the counter in Database 1, Databases 2 and 3 might still show the old count until they sync up after that 1-minute lag. (RYW – Consistency) (Read your write consistency) RYW (Read-Your-Writes) consistency is achieved when the system guarantees that any attempt to read a record after it has been updated will return the updated value. RDBMS typically provides read-write consistency. When we read immediately, we get old value as there is delayed sync.
Strong Consistency: In strong consistency, all replicas agree on the value of a data item before any of them responds to a read or a write. If a write operation occurs, it’s not considered successful until the update has been received by all replicas. For example, consider a banking transaction. If you withdraw money from an ATM (Database 1), that new balance is immediately propagated to Databases 2 and 3 before the transaction is considered complete. This ensures that any subsequent transactions, perhaps from another ATM (representing Databases 2 or 3), will have the correct balance and you won’t be able to withdraw more money than you have. Even when we read immediately, we get new value as there is Immediate sync.
Functional Requirements vs Non-Functional Requirements:
Functional Requirements are the basic things a system must do. They describe the tasks or processes the system needs to perform. For example, an e-commerce site must be able to process payments and track orders.
Non-Functional Requirements are qualities a system must have. They describe characteristics or attributes of the system. For example, the e-commerce site must be secure (to protect user data), fast (for good user experience), Availability (system shouldn’t be down for very long) and scalable (to support growth in users and orders).
Availability
Availability in terms of information technology refers to the ability of a system or a service to be operational and accessible when users need it. It’s usually expressed as a percentage of the total system downtime over a predefined period.
Let’s illustrate it with an example:
Consider an e-commerce website like Amazon. Availability refers to the system being operational and accessible for users to browse products, add items to the cart, and make purchases. If Amazon’s website is down and users can’t access it to shop, then the website is experiencing downtime and its availability is affected.
In the world of distributed systems, we often aim for high availability. The term “Five Nines” (99.999%) availability is often mentioned as the gold standard, meaning the service is guaranteed to be operational 99.999% of the time, which translates to about 5.26 minutes of downtime per year.
SLA stands for Service Level Agreement. It’s a contract or agreement between a service provider and a customer that specifies, usually in measurable terms, what services the provider will furnish.
Availability
Downtime per year
90% (one nine)
More than 36 days
95%
About 18 days
98%
About 7 days
99% (two nines)
About 3.65 days
99.9% (three nines)
About 8.76 hours
99.99% (four nines)
About 52.6 minutes
99.999% (five nines)
About 5.26 minutes
99.9999% (six nines)
About 31.5 seconds
99.99999% (seven nines)
About 3.15 seconds
To increase the availability of the system:
Strategy
Explanation
Example
Replication
Creating duplicate instances of data or services
Keeping multiple copies of a database, so if one crashes, others can handle requests
Redundancy
Having backup components that can take over if the primary one fails
Using multiple servers to host a website, so if one server goes down, others can continue serving
Scaling
Adding more resources to a system to handle increased load
Adding more servers during peak traffic times to maintain system performance
Geographical Distribution (CDN)
Distributing resources in different physical locations
Using a Content Delivery Network (CDN) to serve web content to users from the closest server
Load-Balancing
Distributing workload across multiple systems to prevent any single system from getting overwhelmed
Using a load balancer to distribute incoming network traffic across several servers
Failover Mechanisms
Automatically switching to a redundant system upon the failure of a primary system
If the primary server fails, an automatic failover process redirects traffic to backup servers
Monitoring
Keeping track of system performance and operation
Using monitoring software to identify when system performance degrades, or a component fails
Cloud Services
Using cloud resources that can be scaled as needed
Using cloud-based storage that can be increased or decreased based on demand
Scheduled Maintenances
Performing regular system maintenance during off-peak times
Scheduling system updates and maintenance during times when user traffic is typically low
Testing & Simulation
Regularly testing system performance and failover procedures
Conducting stress tests to simulate high load conditions and ensure the system can handle it
CAP THEOREM
The CAP theorem is a fundamental principle that specifies that it’s impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
Consistency (C): Every read from the system receives the latest write or an error.
Availability (A): Every request to the system receives a non-error response, without guarantee that it contains the most recent write.
Partition Tolerance (P): The system continues to operate despite an arbitrary number of network failures.
Let’s illustrate this with an example:
Think of a popular social media platform where users post updates (like Twitter). This platform uses a distributed system to store all the tweets. The system is designed in such a way that it spreads its data across many servers for better performance, scalability, and resilience.
Consistency: When a user posts a new tweet, the tweet becomes instantly available to everyone. When this happens, it means the system has a high level of consistency.
Availability: Every time a user tries to fetch a tweet, the system guarantees to return a tweet (although it might not be the most recent one). This is a high level of availability.
Partition Tolerance: If a network problem happens and servers can’t communicate with each other, the system continues to operate and serve tweets. It might show outdated tweets, but it’s still operational.
According to the CAP theorem, only two of these guarantees can be met at any given time. So, if the network fails (Partition), the system must choose between Consistency and Availability. It might stop showing new tweets until the network problem is resolved (Consistency over Availability), or it might show outdated tweets (Availability over Consistency). It can’t guarantee to show new tweets (Consistency) and never fail to deliver a tweet (Availability) at the same time when there is a network problem.
CA in a distributed system:
Correct, in a single-node system (a system that is not distributed), we can indeed have Consistency and Availability (CA) since the issue of network partitions doesn’t arise. Every read receives the latest write (Consistency), and every request receives a non-error response (Availability). There’s no need for Partition Tolerance since there are no network partitions within a single-node system.
However, once you move to a distributed system where data is spread across multiple nodes (computers, servers, regions), you need to handle the possibility of network partitions. Network partitions are inevitable in a distributed system due to various reasons such as network failures, hardware failures, etc. The CAP theorem stipulates that during a network partition, you can only have either Consistency or Availability.
That is why it’s said you can’t achieve CA in a distributed system. You have to choose between Consistency and Availability when a Partition happens. This choice will largely depend on the nature and requirements of your specific application. For example, a banking system might prefer Consistency over Availability, while a social media platform might prefer Availability over Consistency.
Stateful Systems vs Stateless systems:
Stateful Systems
Stateless Systems
Definition
Systems that maintain or remember state of the interactions.
Systems that don’t maintain any state information from previous interactions.
Example
E-commerce website remembering items in your shopping cart.
HTTP protocol treating each request independently.
There are different ways like: WebSocket, Server-Sent Events (SSE), Polling, WebRTC, Push Notifications, MQTT, Socket.IO
Polling
In the context of client-server communication, polling is like continually asking “do you have any updates?” from the client side. For example, imagine you’re waiting for a friend to finish a task. You keep asking “Are you done yet?” – that’s like polling.
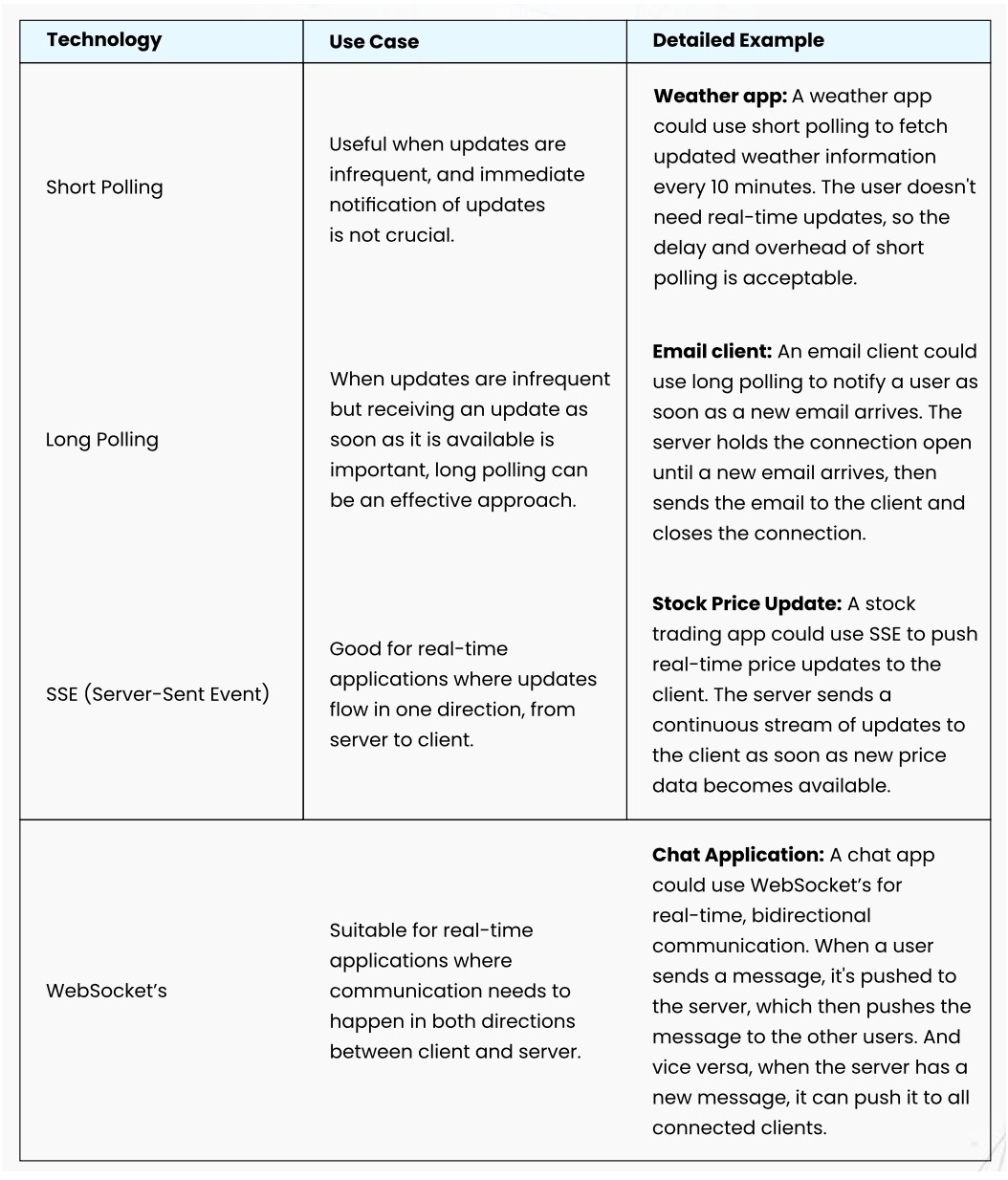
Short Polling:
In short polling, the client sends a request to the server asking if there’s any new information. The server immediately responds with the data if it’s available or says “no data” if it’s not. The client waits for a short period before sending another request. It’s like asking your friend “Are you done yet?” every 6 minutes.
Advantages:
Simple to Implement: Short polling is simple and requires little work to set up. It doesn’t require any special type of server-side technology.
Instantaneous Error Detection: If the server is down, the client will know almost immediately when it tries to poll.
Disadvantages:
High Network Overhead: Short polling can cause a lot of network traffic as the client keeps polling the server at regular intervals.
Wasted Resources: Many of the requests might return empty responses (especially if data updates are infrequent), wasting computational and network resources.
Not Real-Time: There is a delay between when the new data arrives at the server and when the client receives it. This delay could be up to the polling interval.
Long Polling:
In long polling, the client asks the server if there’s any new information, but this time the server does not immediately respond with “no data”. Instead, it waits until it has some data or until a timeout occurs. Once the client receives a response, it immediately sends another request. In our friend example, it’s like asking “Let me know when you’re done” and waiting until your friend signals they’ve finished before asking again.
Advantages:
Reduced Network Overhead: Compared to short polling, long polling reduces network traffic as it waits for an update before responding.
Near Real-Time Updates: The client receives updates almost instantly after they arrive on the server, because the server holds the request until it has new data to send.
Disadvantages:
Complexity: Long polling is more complex to implement than short polling, requiring better handling of timeouts and more server resources to keep connections open.
Resource Intensive: Keeping connections open can be resource-intensive for the server if there are many clients.
Delayed Error Detection: If the server is down, the client might not know until a timeout occurs.
WebSocket:
WebSocket is a communication protocol that provides full-duplex communication between a client and a server over a long-lived connection. It’s commonly used in applications that require real-time data exchange, such as chat applications, real-time gaming, and live updates.
How WebSocket work:
Opening Handshake: The process begins with the client sending a standard HTTP request to the server, with an “Upgrade: WebSocket™ header. This header indicates that the client wishes to establish a WebSocket connection.
Server Response: If the server supports the WebSocket protocol, it agrees to the upgrade and responds with an “HTTP/1.1101 Switching Protocols” status code, along with an
“Upgrade: WebSocket™ header. This completes the opening handshake, and the initial HTTP connection is upgraded to a WebSocket connection.
Data Transfer: Once the connection is established, data can be sent back and forth between the client and the server. This is different from the typical HTTP request/response paradigm; with WebSocket, both the client and the server can send data at any time. The data is sent in the form of WebSocket frames.
Pings and Pongs: The WebSocket protocol includes built-in “ping” and “pong” messages for keeping the connection alive. The server can periodically send a “ping” to the client, who should respond with a “pong”. This helps to ensure that the connection is still active, and that the client is still responsive.
Closing the Connection: Either the client or the server can choose to close the WebSocket connection at any time. This is done by sending a “close” frame, which can include a status code and a reason for closing. The other party can then respond with its own “close” frame, at which point the connection is officially closed.
Error Handling: If an error occurs at any point, such as a network failure or a protocol violation, the WebSocket connection is closed immediately.
Key Differences (Long-Polling vs WebSocket):
Bidirectional vs Unidirectional:
WebSocket’s provide a bidirectional communication channel between client and server, meaning data can be sent in both directions independently.
Long polling is essentially unidirectional, with the client initiating all requests.
Persistent Connection:
WebSocket’s establish a persistent connection between client and server that stays open for as long as needed.
In contrast, long polling uses a series of requests and responses, which are essentially separate HTTP connections.
Efficiency:
WebSocket’s are generally more efficient for real-time updates, especially when updates are frequent, because they avoid the overhead of establishing a new HTTP connection for each update.
Long polling can be less efficient because it involves more network overhead and can tie up server resources keeping connections open.
Complexity: WebSocket’s can be more complex to set up and may require specific server-side technology. Long polling is easier to implement and uses traditional HTTP connections.
Server-Sent Events (SSE):
Server-Sent Events (SSE) is a standard that allows a web server to push updates to the client whenever new information is available. This is particularly useful for applications that require real-time data updates, such as live news updates, sports scores, or stock prices.
Here’s a detailed explanation of how SSE works:
Client Request: The client (usually a web browser) makes an HTTP request to the server, asking to subscribe to an event stream. This is done by setting the “Accept” header to “text/event-stream”.
Server Response: The server responds with an HTTP status code of 200 and a “Content-Type” header set to “text/event-stream”, From this point on, the server can send events to the client at any time.
Data Transfer: The server sends updates in the form of events. Each event is a block of text that is sent over the connection. An event can include an “id”, an “event” type, and “data”. The “data” field contains the actual message content.
Event Handling: On the client side, an EventSource JavaScript object is used to handle incoming events. The EventSource object has several event handlers that can be used to handle different types of events, including “onopen’, “onmessage’, and “onerror”.
Reconnection: If the connection is lost, the client will automatically try to reconnect to the server after a few seconds. The server can also suggest a reconnection time by including a “retry” field in the response.
Closing the Connection: Either the client or the server can choose to close the connection at any time. The client can close the connection by calling the EventSource object’s “close” method. The server can close the connection by simply not sending any more events.